図3.1: RFCが掲示されているWebページ
新しい情報化社会の到来は、 私達のコミュニケーションのあり方を大きく変えてきています。
本章では、 インターネットによる情報流通の方法などについて説明します。
ここまでで、 WWWを使って情報を取り出すやり方や、 その際に考えなければいけないことを学びました。 この節では原理に立ち帰って、 ネットワークの原理やしくみについて学びます。
電子情報ネットワークまたはコンピュータネットワークとは、 複数のコンピュータシステムが相互に自律的に情報をやりとり (通信) できるように構成されたシステム (ハードウェアとソフトウェアの複合体) のことを言います。 この場合自律的とは、 それぞれのコンピュータが、 いつどんな情報をやりとりするかを独自に (他のコンピュータに指示されてでなく) 決定し実行することを言います。
たとえば、 あなたがブラウザであるページを開くと、 手元のコンピュータはそのページに含まれている情報をサーバが動いているコンピュータから取り寄せますが、 前にそのページを表示したときの情報が残っていれば取り寄せを省略することもできます。 どちらにするかは、 手元のコンピュータの内部で自律的に判断するわけです。
一般に 「ネットワーク」 と言った場合、 人と人とのつながりや、 テレビなどの放送網や、 鉄道など交通機関の連携しているようすを指すこともありますが、 以下では電子情報ネットワークのことを指して単に 「ネットワーク」 と記すことにします。
あるコンピュータから別のコンピュータに情報を伝えるには、 それらの間で情報をやりとりするための通信路 (communication path) が必要です。 通信路を構成する手段のことを通信媒体と呼びます。 たとえば普通の電話では通信媒体は銅線ですが、 携帯電話では (基地局までは) 電波ということになります。
コンピュータどうしの通信では、 媒体は銅線か光ファイバーが一般的ですが、 その上での伝送方式としてさまざまなものが使われており、 それに応じてケーブルの規格や本数や配線のつながり方も変わります。
コンピュータで使われる伝送方式は、 すべて0/1から成るディジタル情報を伝えるディジタル伝送であるという点が、 テレビやラジオやオーディオなどの場合と比べて大きな違いになっています。
1つの通信路が、 何種類かの通信媒体や伝送方式を組み合わせて構成されることもよくあります。 その場合は、 通信媒体や伝送方式が切り替わる場所にそのための中継装置が必要になります。
1つの組織 (学校や企業など) の内部で、 局所的なネットワークを構成したものをローカルエリアネットワークないしLANと言います。 皆さんが実習に使っているコンピュータどうしはLANの機器でつながっています。 LANの規模は、 1つの部屋の中だけに収まるものから、 ビル全体や1つのキャンパス全体にまたがるものくらいまで考えることができます。
LANではコンピュータどうしの距離が近いため、 高速な通信が可能です。 このため、 LANは次のような用途に使われています。
LANよりも広い範囲にまたがるネットワークを広域ネットワークないしWANと呼びます。 みなさんのコンピュータとインターネットを接続しているのはWANの機器です。 WANには、 たとえば大学の複数のキャンパスや企業の複数の事業所を結んだWAN、 同一の目的を持つ組織が相互接続してできたWAN、 通信事業者が構築したWANなどがあります。
WANはコンピュータどうしの距離が離れているためLANほど高速な通信はできませんが、 離れた距離にある利用者どうしの通信手段や共同で作業をするための手段として多く使われています。
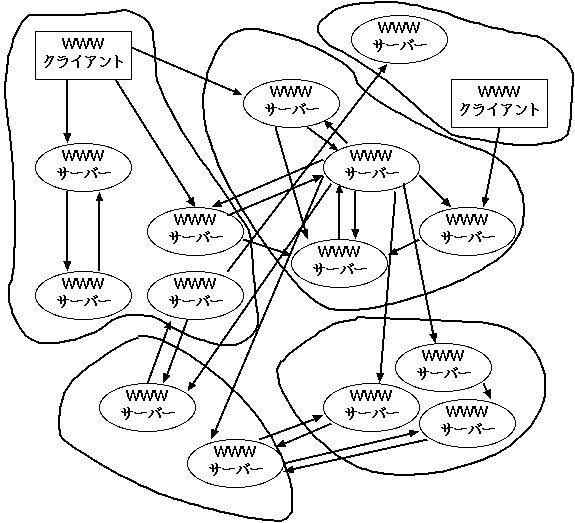
インターネットには、 「サーバー」と 呼ばれるコンピュータと、 サーバーに接続する 「クライアント」 と呼ばれるコンピュータがあります。
さらに、 サーバー同士はインターネットで接続されていて、 異なるサーバーを使っているクライアント同士でも情報交換ができるようになっています。 こうすることで、 利用者は自分の使うコンピュータの近いところにあるサーバーを用いれば、 遠くの人とも情報のやりとりができるようになったのです。
------- | クライアント| ------- 転送要求↓ ↑情報公開 ------- | サーバー | ------- ↓ ↑ (インターネット) ↓ ↑ ------- | サーバー | ------- 情報公開↓ ↑転送要求 ------- | クライアント| -------
また、 サーバーとクライアントの通信は直接行なわれているように見えます。 もちろん、 直接とはいっても実際には何台もの機械による通信内容の中継・転送が行なわれますが、 どのような機械が間に入っているかについていちいち考えなくても相手と直接に通信が出来ているように見えるようになっています。
せっかく、 サーバー同士がインターネットで接続されていても、 お互いの情報の形式が異なっていると、 相互に情報流通をさせることは出来ません。 そこで、 このような問題点を回避するために、 さまざまな約束が決められ、 そうして多くの情報が異なるサーバー同士の間を行き来するようになりました。 サーバーとクライアントの間の通信でも同じです。
この約束のことを、 「通信規約」 といいますが、 あたかも 「コンピュータ同士が会話するための約束」 に見えるので、 この約束を 「言語」 ということもあります。
インターネットでは、 NIC(Network Information Center) という組織が管理・ 流通させているRFC(Request For Comment) と呼ばれる規格があります。 インターネットを用いて情報を流通させる人は、 このRFCの規約に従った情報を流通させる必要があります。
1970年代中頃、 アメリカのARPANETと呼ばれるネットワークがありました。 ARPANETは、 情報の転送経路にいろいろな障害があっても、 障害を回避して別の転送経路に自動的に切り替わったり、 大きなデータを細かく分割して発信し、 受けとる側でそれを元のデータに復元する、 すぐれた機能がありました。 ARPANETの用いる通信方式はアメリカの大学・研究施設などに広まり、 さらなる改良を受けて、 より多くの大学を接続するようになりました。 これが、 「インターネット」 のはじまりで1983年頃の話です。
インターネットは英語で、 「The Internet」 です。 Theがついて、 大文字で始まります。
コンピュータネットワークの特徴の1つに、 2つのネットワークが直接つながっていなくても、 いくつかのネットワークを介して間接的につながっていさえすれば通信が可能だということが挙げられます。 つまり、 ネットワークAのマシンaから間にあるネットワークB、 Cを経由してネットワークDのマシンdに到達することができるのです (図3.2)
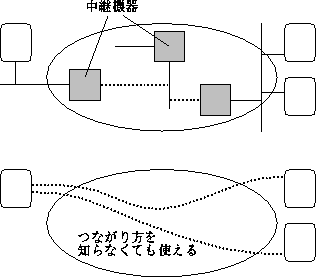
これをさらに発展させて、 国をまたがって多くのネットワークを相互に接続していくことで、 これらすべてのネットワークに含まれるすべてのマシンが相互に通信できるようになります。 この 「夢のようなこと」 を現実にしたのがインターネットで、 これはつまり 「世界中にまたがるネットワークのネットワーク」 なのです。
インターネットは 「ネットワークの集合体」 ですから、 単一の管理組織のようなものは存在しません (インターネットに関わるネットワーク共通の規約や技術を話し合う組織は存在しますが)。 ただし実際にインターネットを利用する上では、 個人や学校がインターネットプロバイダ (料金を取ってネットワークに接続させてくれる企業) と契約したり、 ネットワークプロジェクト (研究、 教育、 その他の目的で共同で資金を出してネットワークを維持しているもの) に参加することになりますから、 そのプロバイダやプロジェクトの規約に従うことは必要です。
電子メールやネットニュースで用いられる文書やWWW用に書かれたHTMLドキュメントのことを、 本書では 「インターネットメッセージ」 と呼びます。
インターネットは世界中に広がっています。 インターネットメッセージを送ったり情報検索を行なったりするということは、 そのまま、 世界中の人々と会話を行なうということになります。
本節では、 私たちの住む地球上におけるインターネットを使った情報流通のあるべき姿について考えます。
インターネットメッセージには、 それぞれ異なる情報流通の方向性があります。 自分が発信したい情報、 受け取った情報が誰から誰に向けて発信されたものであるのかを把握することが大切です。
電子メールとは、 日常生活における 「はがき」 や 「手紙」 に相当するものです。 つまり、 個人的な内容を、 コンピュータの利用者に知らせる仕組み、 そこで知らされた内容が電子メール (郵便局が取り扱っている 「電子郵便」 とは別物です。 ) と呼ばれます。
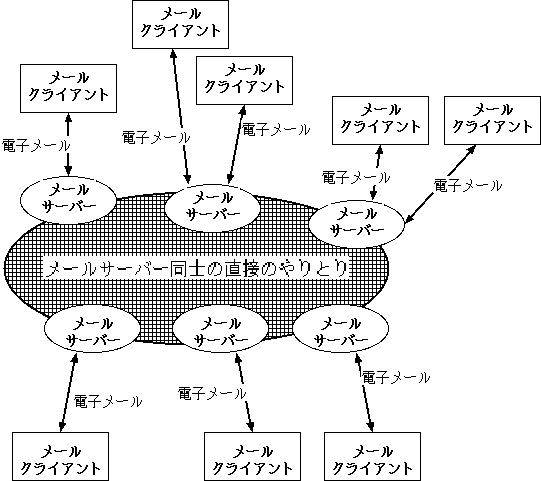
電子メールをインターネットを通じてやりとりするために、 利用者は電子メールに 「宛先 (メールアドレス, E-mail address) 」 をつけて、 自分のコンピュータからインターネットに接続されているメールサーバーと呼ばれるコンピュータに送ります。 メールサーバーは、 電子メールに付けられている宛先を解釈して、 受取人の使うメールサーバーに電子メールを転送します。 受取人は自分の使うメールサーバーにアクセスをして、 自分宛の電子メールを取り出します。
電子メールにネットワーク管理者がある設定をすると、 電子メールをグループ討論などを行なうことが出来ます。 この仕組みや参加者のグループを 「メーリングリスト」 といいます。 同人誌のようなものと考えてもいいでしょう。
例えば、 「スポーツと旅行についての情報交換をする人」 のメールアドレス一覧をメールサーバーに登録しておき、 そのリスト全体の名前として
sports-and-travel@abc.def.ghi.jk
というメールアドレスを設定します。 そうすると、
To: sports-and-travel@abc.def.ghi.jk
で送られた電子メールは、 そのグループのメンバー全員に配布されるという仕掛けです。
グループといっても、 その人数はさまざまです。 現実には、 数人程度のメーリングリストから、 数千人位の規模のものまでさまざまです。 メーリングリストを使うと、 後述するネットニュースとはまた違った意味で、 多対多の情報交換が出来ます。
メーリングリストには、 広く公開されているものもあれば、 参加している人達以外には公開されていないものもあります。 また、 公開されているメーリングリストにも、 新規メンバーの参加を歓迎しているものも、 誰かの紹介がないと新規参加できないものもあります。
なお、 電子メールは基本的に私信として考えるべきですが、 メーリングリストになると、 私信とは言えなくなります。 従って、 届いた情報の取り扱いや発言の際の注意点などは、 私信的な側面と、 公開されている側面の両方に注意して考える必要があります。
インターネットには、 多対多で文字を使った情報流通の仕組みとして、 ネットニュースと呼ばれる仕組みがあります。 ネットニュースとはいっても報道をしているわけではなく、 多くの利用者が自分の意見を表明したり、 議論をしたり、 教えたり教えてもらったりするための、 「共同掲示版」 のようなものです。
ネットニュースには、 話題別にNewsgroupと呼ばれるものが作られていて、 このNewsgroupを使って、 同じ話題について興味を持つ人同士が情報交換を行ないます。 ある人が、 あるテーマについての内容をNewsgroupに投稿すると、 同じテーマに関心のある人が関連する情報を投稿することで、 情報交換が成立します。
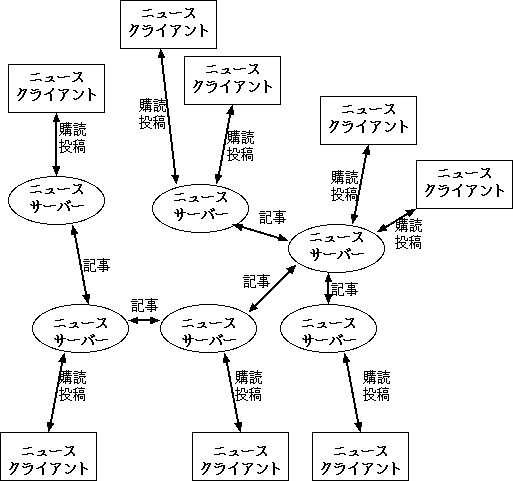
ネットニュースの記事をインターネットを通じてやりとりするために、 利用者はネットニュースの記事にNewsgroups名をつけて、 自分のコンピュータから、 インターネットに接続されているニュースサーバーと呼ばれるコンピュータに送ります。 世界中のニュースサーバーは、 お互いに近くのニュースサーバーと接続をしていて、 手持ちの記事のやりとりをします。 こうすると、 異なる組織にいる人同士で記事の交換が出来るようになります。
WWW
1994年以降になって急速に普及を始めたのが、 World Wide Web、 略してWWWと呼ばれるインターネット上の情報公開システムです。
WWWでは、 Webページと呼ばれる看板のようなものをあらかじめ作成し、 サーバーにその内容を記憶させます。 Webページを見る人は、 サーバーに対してその内容の公開を要求し、 サーバーはその要求に応じて情報を転送します。
また、 Webページを見た人は、 電子メールなどを用いて作成者に連絡をとり、 作成者はさらにWebページに手を加えていきます。
このように、 WWWはネットニュースと同様に、 1対多数の情報交換に用いられます。 しかし、 WWWはネットニュースと異なり、 文字以外の情報流通も出来るように設計されています。 また、 Webページでの話題はそれを作った人が決めているため、 Webページを話題別に分類することは出来ません。 これは、 「共同掲示版」 であるネットニュースとの相違点です。
WWWの場合は、 「WWWサーバー」 と 「WWWクライアント」 による通信によって情報の転送が行なわれることになります。
WWWの場合も、 RFCは重要な役目を果たします。 RFCやRFCで指定される他の規約文書などで、 世界中に散らばるサーバーの中から、 特定のサーバーを選んで情報を引き出す方法、 情報を蓄積する場合の形式・文法などが定められています。
HTML形式とリンク
現在のWWWでは、 多くの場合、 WebページをHTML形式で記述しています。
HTML形式には、 他のWWWサーバーのWebページを指示する書式があります。 情報を引き出す利用者は、 この参照にしたがって、 他のWWWサーバーに接続し直すことが出来ます。 このような 「他のWWWサーバーへの参照を指示する書式」 のことを、 「リンク」 といいます。
リンクを作るためには、 特定のWWWサーバーを指定し、 そのWWWサーバー固有の方法で情報を引き出す必要があります。 このとき用いられるのが、 「URL」 と呼ばれる文字列です。
現在では、 ほとんどのWebページがリンクを持ち、 相互に情報を参照しあっています。 このリンク関係は、 あたかも世界中にクモの巣が張られているように見えます。 実は、 これが 「Web(クモの巣) 」 という言葉の由来です。
Web-BBS
WWWの情報公開機能に、 掲示版の機能をつけたのが、 通称、 Web-BBSと呼ばれるシステムです。 これは、 Webページ内に掲示版を作り、 そこを閲覧した人が意見を書き込んだり、 その意見を他の人が見ることができるというものです。
Web-BBSの場合には、 その掲示版の存在を知っている人ならば誰でもその情報を入手できることから、 私信よりも公開された通信として扱われます。 しかし、 その掲示版の存在を知る人が少ない場合には、 よりプライベートな情報が書き込まれたりすることが多く、 その結果、 知的所有権や、 プライバシーの保護について問題を生じさせてしまいがちなので、 注意が必要です。
インターネットにおいては、 利用者は情報検索者であると同時に情報発信者でもあります。 情報発信者であるということは、 新聞・放送と言ったマスメディアと同じ立場に立つことです。 したがって、 情報発信を行なうには、 その責任を十分に自覚しておくことが大切です。
電子メールの場合にも同様の問題が起こるのですが、 これらの場合は、 書いたものに対する反応が直接に情報発信者の元に届きます。 したがって、 初心者の利用者でも使いながら教育を受けるという側面がありました。 しかし、 WWWの場合は、 作成したHTML文書に対しての反応が直接的に得難いために、 回りからの指摘によって適切な使い方を身につけることが期待しにくくなります。
そこでWebページに掲示版機能などを入れておき、 読んだ人に感想を書き込んでもらうようにしておけば、 反応を得やすくなります。
電子情報ネットワークの上ではさまざまな情報サービスが利用されていますが、 その中でもっとも古くからあるのが電子メール (electronic mail) です。 電子メールはある人から別の人に電子的にメッセージを届けるような情報サービスです。 いわば、 「電子のはがき」 だと思えばよいでしょう。
電子メールは機能的にははがきと似ていますが、 次のような点ははがきより優っています。
電子メールは個人が個人にメッセージを送るものですから、 コンピュータに 「現在コンピュータを使っているのは誰か」 ということを教えなければなりません。 これを利用者の認証と呼びます。 情報サービスの中には認証を必要としないものもありますが、 電子メールではかならず認証が必要です。
典型的には一人一人が自分固有の利用者名 (user ID) を持ち、 また他人に自分の名前をかたられないようにパスワードを設定しておきます。 そして、 コンピュータを使いはじめる時に利用者名とパスワードを正しく打ち込むとはじめて、 コンピュータが使える状態になるようにするのです。 下にそのようなシステムの画面例を示します。 (パスワードはのぞき込まれても分からないように、 画面には表示されません。 )
login: 利用者名 Password: ????????? Welcome ...
電子メールを読み書きするクライアントにもいろいろなものがありますが、 原理的にはどれもさほど違いはありません。 ここでは典型的な電子メールクライアントの動作を、 簡略化した形で示して説明します。
まず、 電子メールクライアントを起動すると、 自分あてに送られて来たメッセージの一覧が表示されます。
01 04/01 taro@kou1.ne.jp エープリルフール 02 04/01 mika@kou1.ne.jp Re: エープリルフール 03 04/02 sense@kou1.ne.jp 昨日の掃除
ここではメッセージごとに次の情報が表示されています (クライアントによって表示の内容や形式に違いがあります)。
メールアドレスは一般に、 「利用者名@ドメインアドレス」 の形をしています。 ドメインアドレスというのはインターネット上で個々のコンピュータを特定する名前で、 ここではその利用者がメールを読み書きする際に使っているメールサーバを実行しているコンピュータを表します。
メッセージを見るには、 矢印キー、 マウス、 メッセージ番号などで見たいメッセージを指定して 「見る」 コマンドを選択します (具体的なやり方はクライアントによって違います)。 次の記事は 「宮城まさ子さん」 が受け取ったメッセージの画面例です。
From: 湘南太郎<taro@kou1.ne.jp> To: 宮城まさ子<masa@kou1.ne.jp> Cc: 先生<sensei@kou1.ne.jp> Subject: エープリルフール Date: Wed, 1 Apr 1998 12:01:30 JST 先生が盲腸で入院したので、 あとでお見舞いに行こうね。
メッセージが長くて1 画面に収まらない場合に下の方を見るやり方や、 見おわって先の一覧画面に戻るやり方なども、 クライアントごとに違っています。
自分から電子メールを送信する場合には、 送り先のメールアドレス (To:)、 主題 (Subject:)、 本文を自分から指定すればよいのです。 なお、 控え先 (Cc:) のアドレスとして自分のアドレスを指定しておけば、 自分がどのようなメールを送信したかの記録になります。
次は、 「宮城まさ子さん」 が先の太郎さんのメールを読んで、 先生あてに送信記事を作成した画面例です。 自分と太郎さんあてにCc:を指定していることに注意してください。
From: 宮城まさ子<masa@kou1.ne.jp>
To: 先生<sensei@kou1.ne.jp>
Cc: 宮城まさ子<masa@kou1.ne.jp>,
湘南太郎<taro@kou1.ne.jp>
Subject: 入院って本当?
太郎さんに聞いたのですが、先生、本当に入院されたのですか。
それって、本当ならメール読めないよね。
また、 この画面では日付の記入はありません。 日付は電子メールを配送するときにコンピュータが自動的につけてくれるのです。
電子メールの返事も電子メールで出すのが普通です。 このときは、 クライアントの 「返信」 機能を使うと、 自動的に送り先などが設定され、 また元のメッセージが引用されるなど返信に便利なように処理がなされます。 次は 「先生」 が先のメールに返信しているときの画面例です。 Cc:に先生と太郎の2人ぶんのアドレスが指定されていることに注意。
From: 先生<sensei@kou1.ne.jp>
To: 宮城まさ子<masa@kou1.ne.jp>
Cc: 湘南太郎<taro@kou1.ne.jp>,
先生<sensei@kou1.ne.jp>
Subject: Re: 入院って本当?
> 先生、本当に入院されたのですか。
私は入院してませんよ。
最初の太郎くんからのメール、主題が
「エープリルフール」
になっていたでしょう?
Cc: をちゃんと見ましょうね。
電子メールの記事は、 その書き方がRFCで詳細に決められています。
まず、 これらのメッセージはヘッダーと呼ばれる部分と、 それ以外の本文の部分に分かれます。 「ヘッダー部分」 とは、 その電子メールの宛先や表題、 発信人、 発信日時などの 「電子メールの属性的な情報」 が書かれた部分です。 それに対して、 「本体部分」 は、 単純に本文の部分となります。 ヘッダーと本体部分は、 1行以上の空行で分割されます。
以下の電子メールの例では、 最初の3行がヘッダー部分で、 4行目がヘッダーを本文を分ける空行、 5行目以降が本文となります。
To: you@mailaddress.a.b.c.d Cc: saito@abc.def.ghi.jk Subject: I will visit to your town. こんにちは、斉藤です。 実は来週の月曜日から3 日間、 出張でそちらの町に行くことになりました。 ということで、夜にどこかで飲みませんか?
上にあるような形は、 送り出す時のヘッダーと本文の例です。 実際にインターネット上を電子メールが転送される場合には、 これらのヘッダーの他に、 転送に必要なヘッダーが付加され、 さらに、 転送の途中で中継が行なわれると、 その記録がどんどんとヘッダーに付加されていきます。 その結果、
Received: from wise19.abc.def.ghi.jk (wise19.abc.def.ghi.jk
[256.9.4.137])by mailaddress.a.b.c.d (8.8.7+2.7Wbeta7)
with ESMTP id SAA29850 for <saito@qabc.def.ghi.jk>;
Sat, 14 Feb 1998 18:22:37 +0900 (JST)
Received: from wise22.abc.def.ghi.jk
(saito@wise22.abc.def.ghi.jk [256.9.4.152])
by wise19.abc.def.ghi.jk (8.8.6/3.6Wbeta5)
with ESMTP id SAA27599;
Sat, 14 Feb 1998 18:22:37 +0900 (JST)
Message-ID: 199802140922.SAA27599@wise19.abc.def.ghi.jk>
Date: Sat, 14 Feb 1998 18:22:37 +0900
From: saito@abc.def.ghi.jk
To: you@mailaddress.a.b.c.d
Cc: saito@abc.def.ghi.jk
Subject: I will visit to your town.
こんにちは、斉藤です。
実は来週の月曜日から3 日間、出張でそちらの町に行くことになりました。
ということで、夜にどこかで飲みませんか?
のようになって届きます。
本節では、 電子メールの宛先となるメールアドレスについて説明します。
メールアドレスとは、 各利用者に宛てて電子メールを送る時の宛先に相当するものです。 RFCでは、 メールアドレスの書き方を定めています。 この規約にしたがって宛先を書けば、 適切に配送されます。 言い替えれば、 メールアドレスの書き方が不適切だと、 電子メールが正しく届かないことになります。
また、 電子メールを送ったときには送り主のメールアドレスをみることで、 誰がそのメールを書いたかがはっきりします。
したがって、 メールアドレスは個人を特定するために大変重要な役割を果たしているのです。
Fromヘッダーには差出人のメールアドレスを書くことになっています。 通常は、 コンピュータにログインする際に入力する 「ログイン名」 などからFromに書くべき内容を自動的に判断して、 電子メールやネットニュース用のソフトがFrom ヘッダーを自動的に生成します。
Toは、 単純に電子メールの送り先を明示するヘッダーです。 一方、 Ccはカーボンコピー (carboncopy) と呼ばれます。 どちらも、 その後ろにメールアドレスを書いておくと、 そのアドレスが電子メールの送付先になります。
もともと、 事務文書などを取り引き相手に送付する場合には、 カーボン紙を送付する文書の下に敷き、 同じ内容を手元にも残す習慣がありました。 カーボン紙とは、 片面 (あるいは両面) に鉛筆の芯を粉にしたようなものを塗り付けた特殊な紙です。 白い紙の上にカーボン紙のこの面が下になるように置き、 さらに、 その上に紙をもう一枚置いてから文字を書くと、 下の紙にも上の紙に書いたのと同じ文字が写る仕掛けです。 このようにして得られた 「複製」 を、 「カーボンコピー」 といいます。 カーボンコピーは、 同じ内容を複数の人に送る必要がある場合にも使うことができます。
この歴史的手法が電子メールにも採り入れられています。 すなわち、 Ccヘッダーとは、 電子メールの自分への保存と、 副宛先への送付を表すヘッダーです。
たとえば、
To: a@x, b@x, c@y Cc: p@k, q@l, saito@abc.def.ghi.jk From: saito@abc.def.ghi.jk
の場合には、 a@x, b@x, c@yが本来の宛先であり、 p@k, q@l, と、 自分のメールアドレスsaito@abc.def.ghi.jkがカーボンコピーによる副宛先です。 このように、 Ccの最後に自分のアドレスを書いておくと、 自分宛の備忘録になるので便利です。
したがって、 もし自分のメールアドレスがCcに含まれている電子メールを受けとった場合には、 送った人は、 自分を 「副宛先」 としてとらえていることになります。 この場合は、 この電子メールに返事をする義務はないと考えても差し支えないでしょう。
一度送り出してしまった電子メールを取り戻すことはできません。 もし、 メールアドレスを間違えて書いてしまって電子メールを出すと、 どうなるでしょうか?
転送の途中で、 そのアドレスが無効であることが分ると、 すぐに送信元のメールアドレスに向けて、 「User unknown」 や 「Host unknown」 といった表題の電子メールが送られてきます。
この電子メールのFromは、 大抵の場合Mailer-Daemonという名前になっています。 この電子メールは、 メールサーバーから自動的に送られてくる電子メールです。 この電子メールに返事を書かないようにしましょう。
まず、 電子メールの中身を確認しましょう。 非常に簡単な英語で書いてありますから、 落ち着いて目を通して下さい。 どの電子メールのどの宛先に宛てた電子メールが配送に失敗したかが書かれています。
「User unknown」 の場合は、 メールアドレスのメールドメインの部分はあっているが、 利用者が見つからないことを意味し、 「Host unknown」 の場合は、 メールアドレスのメールドメインの部分が間違っていることを意味します。
Date: Tue, 17 Feb 1998 10:48:10 +0900
From: Mail Delivery Subsystem <mailer-daemon>
Subject: Returned mail: User unknown
Message-ID: <199802170148.kab00371@abc.def.ghi.jk>
To: saito@abc.def.ghi.jk
Auto-submitted: auto-generated (failure)
The original message was received at
tue, 17 feb 1998 10:48:10 +0900
From saito@abc.def.ghi.jk
---- The following addresses had permanent fatal errors ----
nishizawa@abc.def.ghi.jk
----- transcript of session follows -----
550 nishizawa@abc.def.ghi.jk... User unknown
----- Original message follows -----
Return-path: saito@abc.def.ghi.jk
Received: (From saito@localhost)by abc.def.ghi.jk
(8.8.8+2.7wbeta7/3.4w3)ID kaa00371;
tue, 17 feb 1998 10:48:10 +0900
Date: tue, 17 feb 1998 10:48:10 +0900
Message-ID: <199802170148.kaa00371@abc.def.ghi.jk>
From: Saito Takeshi <saito@abc.def.ghi.jk>
To: nishizawa@abc.def.ghi.jk
Subject: Ohayou gozaimau.
おはようございます。
....
上の例の場合、 nishizawa@abc.def.ghi.jk宛の電子メールに対して、 「nishizawaという利用者が見つからない (User unknown) 」 という理由で電子メールが送り返されています。
書き間違えたメールアドレスが有効なメールアドレスの場合、 つまり、 その他人に送ってしまった場合はどうしようもありません。
この場合は送信が正常に終了してしまうので、 自分で気づくことは滅多にありません。 間違えて送られた相手から連絡があって初めて気がつくのが普通です。 この場合には、 間違って送ってしまった人に謝りの電子メールを送りましょう。 また、 正しい宛先に送り直すことも必要です。
複数のメールアドレスをToやCcに列挙し、 その一部だけが誤ったメールアドレスになってしまっている場合は、 面倒なことになります。 この場合、 これらの電子メールを正常に受けとった人が返事を書くと、 大抵の場合、 元の電子メールのToやCcに書かれているメールアドレスがCcに付加されますが、 それにもまた、 間違ったメールアドレスが含まれてしまいます。 その間違ったメールアドレスが無効な場合には、 返事を書いてくれた人にmailer-daemonからエラー電子メールが届き、 その間違ったメールアドレスが有効な場合には、 送るべきでない人にまでその返事が送られてしまいます。
このような事態に気がついた時は、 なるべく早く、 To,Ccに書かれている全員に訂正情報を流すべきしょう。
本節では、 インターネットメッセージの内容に関わる項目について説明します。
Subjectは、 その電子メールや記事の表題を表します。
表題ヘッダーは 「必須」 のヘッダーではありませんから、 つけなくても構いません。
ところで、 個人的な手紙に表題をつけるのは日常の習慣ではありません。 なぜなら、 手紙を受けとった人は、 Subjectに関係なく、 必ずその中身に目を通すからです。 しかし、 しばらく時間が経ってからその電子メールを検索するときに、 適切なSubjectがついてると便利でしょう。 そのような状況を考えると、 電子メールの場合も、 できる限り適切なSubjectをつけるべきです。
これに対して、 ネットニュースは不特定多数を対象とした発言を行なうので、 その中身を読んでもらうためにSubjectは非常に重要な役割を果たします。
Subjectは、 それを見ただけで中身が分かるようにするべきです。 たとえば、
Subject: question
や
Subject: Oshietekudasai
などでは、 何が書いてあるかが分かりません。 ネットニュースの場合は、 読んでもらわないと情報交換ができなくなるのですから、 内容を明確に表すタイトルをつけることが必要です。
Subject: What is needed for living in England?
や
Subject: 生活雑貨クリエーターになりたいのですが。
と書いてあれば、 知識・興味を持っている人が目を通してくれそうです。
電子メールでもネットニュースでも、 Subjectの文字列の先頭に"Re:"をつけて、 元のメッセージに対する応答を表す慣習があります。 たとえば、 先ほどの例についての返答のSubjectは、
Subject: Re: 生活雑貨クリエーターになりたいのですが。
とします。
ただし、 返信が元の表題から遠く外れた内容になっている場合には、
Subject: 発明コンテスト(Re: 生活雑貨クリエーターになりたいのですが。)
のようにしておくと、 読む人に親切です。
インターネットを用いて発信された電子メールやネットニュースの記事には、 発信した年日時を記録したDateヘッダーというヘッダーがあります。
このDateヘッダーには、 タイムゾーンが付記されているのが普通です。 タイムゾーンとは、 イギリス連邦にあるグリニッジ天文台の南中時刻を正午とする 「世界標準時GMT」 に対して、 それぞれの国・地域における標準時の差を表したものです。
私たちの住む日本は、 GMTに対して9時間進んだ時間を採用しています。 したがって、 日本で正午に発信した電子メールがイギリス連邦の首都であるロンドンにすぐに届いたとすれば、 現地では午前3時に届く (夏時間期間の場合は、 1時間遅い時間になります。 ) ということになります。 この時間に起きている人は多くありませんから、 その電子メールの返事が届くのは、 早くても日本時間で夕方以降になるでしょう。
一方、 同じ正午にアメリカ合衆国の首都ワシントンに向けて送られた電子メールがすぐに到着したとすれば、 そのとき現地は前日の午後10時です。 この電子メールも、 同じようにすぐに返事をもらうことは期待できません。
Dateヘッダーは、 例えば、
Date: Thu, 05 Mar 1998 00:32:27 +0900
や
Date: Wed, 04 Mar 1998 09:46:19 -0600
や
Date: Wed, 04 Mar 1998 16:49:29 +0100
のように書かれます。
に付きます。
ちなみに、 最初の電子メールが木曜日発信で、 次の2通が水曜日発信の電子メールになっていますが、 時間の経過をタイムゾーンと日付変更線を含めて考えれば、 日本からの電子メールが一番古い電子メールになります。
日本国内のタイムゾーンは、 上の表記の他に、
Thu, 05 Mar 1998 00:32:27 GMT+0900
や
Thu, 05 Mar 1998 00:32:27 JST
などの書き方があります。
受けとった電子メールの内容について自分の返答・回答・意見・反論といった 「反応」 を行なうことがあります。 こういった反応を、 「リプライ」 とか 「フォローアップ」 などということもあります。
その際には、 「どの電子メール・記事への」「どの部分に対する」 反応であるかを示す必要があります。
この場合には、 その反応を読む人が使う電子メールクライアントソフトのために、 ヘッダーを使って参照元のMessage-IDを示し、 さらに、 読む人のために、 参照・引用を行なう必要があります。
本節では、 そのようなときの方法について説明します。
一つ一つの電子メールには、 Message-IDと呼ばれる文字列がついています。 例えば、
From: Saito Takeshi <saito@abc.def.ghi.jk>
To: you@abc.def.ghi.jk
Subject: Re: test mail
Message-ID: <199802230326.maa16387@abc.def.ghi.jk>
これは、
テストメールです。
--
Saito Takeshi
saito@abc.def.ghi.jk
の場合には、 <199802230326.maa16387@abc.def.ghi.jk>の部分が、 Message-IDです。
電子メールや記事に対して返信・フォローなどを行なうときには、 Message-ID は 「どの電子メール・記事に対しての返事であるかをはっきりさせる」 という重要な役割を果たします。
主に電子メールの場合に用いられるヘッダーです。
From: Saito Takeshi <saito@abc.def.ghi.jk>
To: you@abc.def.ghi.jk
Subject: Re: test mail
In-reply-to: your message of "mon, 23 feb 1998 12:25:59 jst."
<199802230326.maa16387@abc.def.ghi.jk>
これは、
テストメールです。
--
Saito Takeshi
saito@abc.def.ghi.jk
のように書きます。
大抵の場合は、 電子メールクライアントが自動的に作ってくれるので、 利用者は何も気にしなくても大丈夫です。
Referencesヘッダーは、 発言の元となった電子メールのMessage-IDを示します。
From: Saito Takeshi <saito@abc.def.ghi.jk>
Newsgroups: ugougo.rec.drums
References: <1997023420320.MAA13487@seloir.asb.cest.ff>
Subject: Re: TEST Mail
In-reply-to: Your message of "Mon, 23 Feb 1998 12:25:59 JST."
<199802230326.MAA16387@abc.def.ghi.jk>
お返事ありがとうございます。
......
のように書きます。
In-reply-Toと同じように、 クライアントが自動的にReferencesヘッダーを作りますので、 利用者は特に意識する必要はありません。
引用とは、 他者の書いたものを自分の文書の一部に使うこと (第3.3.7節) です。 なお、 他者の書いたものを自分が書いたように見せて使うことは 「盗用」 にあたり、 引用ではありません。 引用は著作権法で規定され、 判例などで実際の運用についての見解も示されていますので、 それに従うべきでしょう。
実際のメッセージの引用では、 引用されている部分を明確にするために、 各行の先頭に">"などの記号や"Saito>" のように発言者がわかる記号を書いたりします。
From: youichi@abc.def.ghi.jk To: Saito Takeshi <saito@abc.def.ghi.jk> Subject: Re: test mail > これは、テストメールです。 > とどいたら返事を下さい。 届きました。 お久しぶりです。 メールアドレス変わったんですね。
や
From: ax@etoil.espace.wsd.ff To: Nishizawa Takeshi <nishi@abc.def.ghi.jk> youichi@abc.def.ghi.jk Subject: Re: test mail Nishizawa>こんにちは。 Nishizawa>暑くなりましたね。 youichi> まったく暑いですね。 youichi> お元気ですか? なるほど、日本はもう夏ですか。 .....
のように書きます。
このような引用の方法も、 多くの電子メールクライアントで自動的に対応してくれます。
一つの電子メールに複数のテーマが出てきた場合、 内容が散漫にならないように、 テーマを分割して、 複数の電子メール・記事として反応することも、 場合によっては議論の流れをきれいにする有効な手段です。
このような場合には、 分割されたテーマについての反応であることをはっきりとさせるために、 表題を書き直すべきでしょう。
皆さんはインターネットということばについて聞いたことがあると思います。 インターネットとは、 世界中のコンピュータどうしを互いにつないで情報をやりとりできるようにしたものです。
インターネットにつながったコンピュータからは、 さまざまな方法で情報を取り出すことができます。 たとえば、 離れたところにいる知合いから電子メールと呼ばれる 「コンピュータの上でのはがき」 をもらうことで情報を取り出すことも、 ネットニュースと呼ばれる「 コンピュータの上での新聞」 を読むことで情報を取り出すこともできます。
ここでは最初の一歩として、 ワールドワイドウェブ、 または略してWWWとかWeb とも呼ばれる、 いわば 「コンピュータの上での壁新聞」 からさまざまな情報を取り出してみましょう。
WWWはインターネット上で情報をやりとりする仕組みの1つで、 1995年ころから急速に普及しました。 WWWでは、 情報を見るのにWebブラウザと呼ばれるプログラムを使います。 ブラウザはインターネットを通じて各地にあるWebサーバと呼ばれるプログラムに接続して情報を取り出してきます。 サーバが情報源、 ブラウザが情報を受け取る手段ということになりますね (図3.6)。
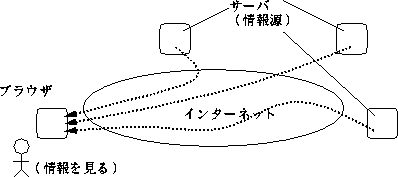
テレビ放送で言えば、 Webサーバは放送局、 Webブラウザはテレビ受信器に当たります。 ただし、 テレビは電波やケーブルの届く範囲の放送局の情報しか受け取れませんが、 WWWでは世界中の数十万箇所にある、 どこのWebサーバの情報でも受け取れますし、 混信することもありません。
WWWでは受け取る情報の単位はWebページと呼ばれ、 ブラウザの画面上で画像とテキスト (文字) のまざった形で眺めることができます。 また、 ページの中には音声や動画を含めることもできます。 このように、 コンピュータで多く使われるテキスト情報以外の各種形態の情報を使用可能なことから、 WWWはマルチメディアのシステムであると言います。
WWWではさらに、 ページ内のリンクと呼ばれる部分を選択すると、 それぞれのリンクが指している別のページが取り出されて表示されます。 このように、 複数の情報単位が相互に関連づけられ、 その関連をたどることで情報を取り出して行けるようなシステムのことをハイパーテキストと言います。
以上を整理すると、 WWWとは、 インターネット上のハイパーテキストに基づくマルチメディア情報システムだといえます。 なお、 World Wide Webをそのまま訳すと 「世界中にまたがったクモの巣」 で、 多数のページが網目のようにリンクで結ばれているようすからこう名付けられたものです。
ではそろそろ、 WWWで実際に情報を見てみましょう。 コンピュータでWebブラウザを起動すると、 設定されている初期画面 (図3.7) が表示されます。
ここで、 表示されたページの中に下線つきで表示されている箇所は、 そこがリンクであることをあらわします。 そこにマウスカーソルを持っていくと、 画面下端に文字列が表示されます。 これがリンクの指している先の 「番地」 を表します。 この状態でマウス左ボタンを押すと (この操作を 「リンクを選択する」 といいます)、 ブラウザの画面が切り替わって指した番地のページが表示されます。
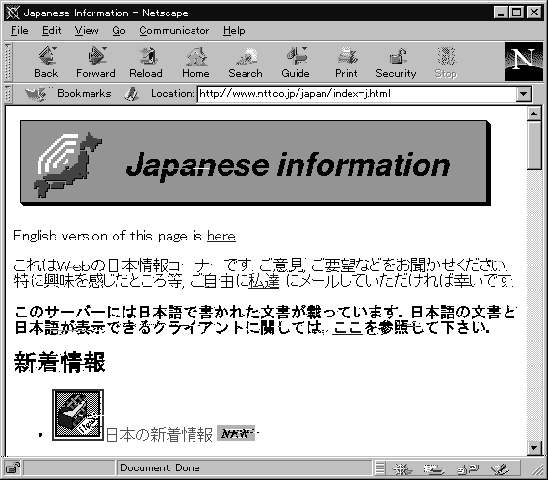
図3.8は先の画面で 「日本の情報」 と記されたリンクを選択したときの表示です。 このページには日本に関するさまざまな情報が表示されています。
このページはかなり内容が多いので、 窓の右側にスクロールバーが表示されています。 その中の四角い箱 (エレベータ) をマウスでドラグすると、 画面が上下にスクロールして、 ページの下の方を見ることができます。 このページからさらに、 さまざまなページへのリンクをたどって多くの情報を見ることができます。
リンクをたどって内容を見たあと、 さっきのページへ戻りたければ、 窓の上の方にある左矢印のボタンを選びます。 また、 迷子になってしまっていちばん最初のページへ戻りたければ家の絵のボタンを選びます。 このようにして、 WWW ではリンクと各種のボタンを選択するだけで、 世界中のさまざまな情報をたどっていくことができます。
先に、 リンクの上にマウスカーソルが置かれると 「リンクが指している番地」 が見えることを説明しました。 そして、 リンクを選択すると新しいページが表示されます。 またリンクによっては、 新しいページが表示される代わりに音が出たりするかも知れません。
このように、 WWWが扱うネットワーク中のさまざまなものWebページや音や画像やその他のものには、 すべて 「番地」 がついています。 この番地の形式のことをUniform Resource Locator、 略してURLと呼びます。 たとえば 「日本の情報」 ページは
http://www.ntt.co.jp/japan/index-j.html
というURLを持っていました。 ページが表示されるとき、 ブラウザの窓の上方にこのURLが表示されているはずです。
URLのうちの先頭部分 「http:」 は、 それに続く部分がWebサーバから取り寄せるページであることを表しています。 たとえば電子メールの宛先や電子ニュースの記事番号を表すURLではこの部分が別のものになります。

これはたとえば、 ある人に情報を伝えるのにはがき、 電話などいくつもの方法がありますから、 それらを統一して
葉書:〒100 千代田区大手町1-1-1 電話:03-1234-5678 FAX:03-1234-4321
のように書き表すものだと考えればよいでしょう。 つまりURLはかなり広い意味での 「番地」 を統一的に書き表したものなのです。
その次の 「//」 から 「/」 までの間は、 その情報を提供しているWebサーバが動いているコンピュータの名前を表します。 その後の部分は、 サーバ中で情報を格納してある位置を表します。
新聞広告や、 商品の箱などに、 宣伝用のページのURLが記載されているのもよく見かけます。 そのページが見たければ、 ブラウザのURL表示窓にそのURLを打ち込んでリターンキーを押すと、 そのページが表示されます。
しかしせっかくコンピュータがあるのに、 なぜわざわざ新聞広告でURLを教えているのでしょう? それは、 あるページを見るには、 何らかの方法でそのURLを教えてもらわなければならないからです (別のページからリンクしてもらう、 というのも 「教えてもらう」 方法の1つですね)。 ちょうど、 電話番号というとても便利な 「番地」 も、 はがきや名詞や電話帳で相手に伝えないと役に立たないのと同じだと言えます (片方が相手の電話番号を知っていれば電話を掛けて教えることもできますね)。
次々にリンクをたどりながらページを見ていくのは、 漠然とどんな情報があるか眺める (これをブラウズする、 といいます) のにはよい方法ですが、 特定のことがらについて調べようとする場合にはあまり向いていません。 WWWでそのような場合に利用できるサービスとして、 ディレクトリサービスと検索サービスがありますから、 これらについて見ていきましょう。
ディレクトリサービスというのは、 さまざまな情報を持ったWebページを、 情報の種類ごとに分類整理して示すようなサービスを言います (ディレクトリとは 「登録簿」 という意味です)。 図3.10にそのようなサービスの1つのページを示します。
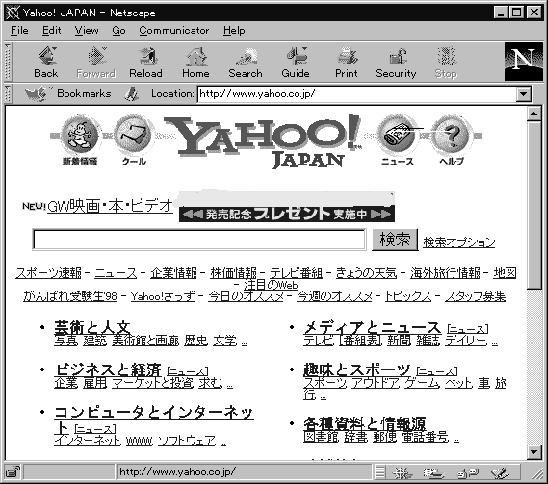
これを見ると、 各種の情報が分類別に整理されているのが分かります。 ここでたとえば 「趣味とスポーツ」 のリンクを選択すると、 今度は趣味とスポーツに関係するさまざまな分類が現われ、 そこからリンクを選ぶとさらに細かい分類に行ける、 というふうに階層構造になっているわけです。
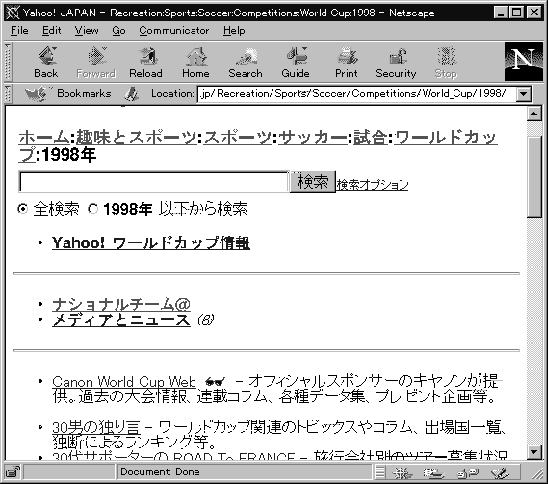
図3.11は入口から順に 「趣味とスポーツ」→「スポーツ」→「サッカー」→ 「試合」→「ワールドカップ」→「1998年」 とだとったページのようすです。 ここに1998年サッカーワールドカップに関係するページへのリンクが多数登録されていて、 興味のあるものをたどることができます。
このように、 ディレクトリサービスでは情報がきちんと分類整理してあるため、 その分類に沿って探すことで欲しい情報に到達できます。 また、 それぞれのページをどこに登録するかは人間が判断しているので、 無意味な情報に到達してしまうことはあまりありません。 その反面、 誰かが登録したページしか探すことができない、 という弱点があります。
ところで、 情報の分類のしかたはひと通りではありません。 たとえば、 「コウモリ」 は動物ですが、 「飛ぶもの」 という分類を考えれば鳥やモモンガと一緒に分類してもよいわけです。 そして、 紙の百科辞典などと違い、 WWWではある1 つのページを複数の視点から分類することが簡単にできます (両方の分類からリンクを張ればいいだけですから)。
しかし、 そうは言ってもあらゆる分類方法をあらかじめ用意しておくことはできませんから、 ディレ クトリサービスではよく使われそうないくつかの分類方法を選んでその枠組みに沿った分類を行います (サービスの提供元によってそれぞれ分類のしかたも違います)。 それがあなたがいつも使っている分類方法と違っていると、 なかなか探しているものを見つけることができなかったりします。
特定の情報を効率よく探すもう1つの手段は、 検索サービス (検索エンジンと呼ばれることもあります) を利用することです。 検索サービスでは、 分類をたどる代わりにWebページの入力欄に直接探したいものをあらわす言葉を打ち込むことで情報を探していきます。
サッカー | ワールドカップ | 1998
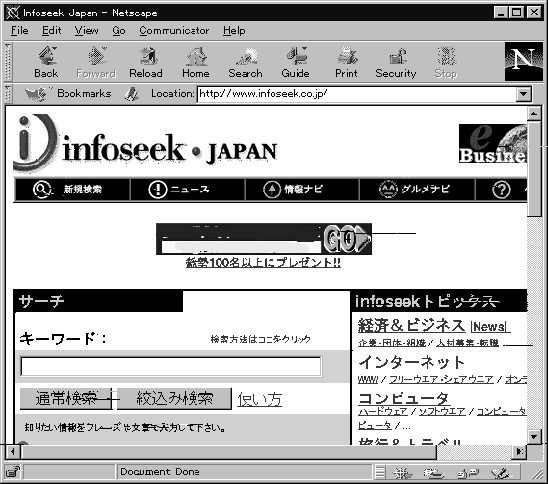
図3.12に、 とある検索サービスの入口ページを示します。 ここで 「キーワード」 と記された欄に 「サッカー」 と記入して 「通常検索」 と書かれたボタンを選択すると、 「サッカー」 という言葉を含んだWebページをすべて集めて、 言葉の出現頻度が高い順に並べて上位のものを表示します。
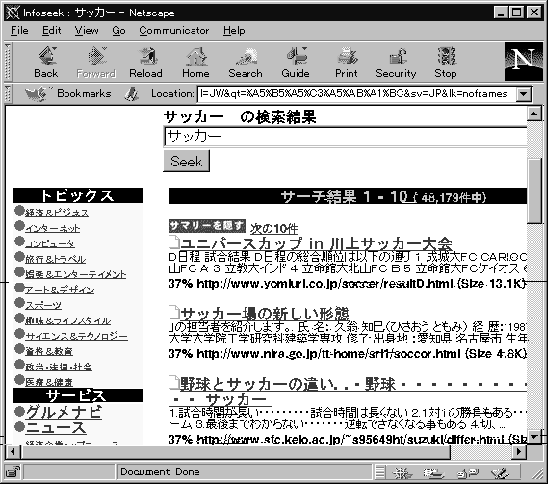
図3.13にその結果を示していますが、 これを見ると見つかったページが48,179 件あり、 そのうちから上位10件を表示しています。
今知りたいのは1998年ワールドカップに関することだけなので、 その特定の項目だけを調べましょう。 入力欄を修正して、 「サッカー」 の後に 「|」 で区切って 「ワールドカップ」 と 「1998」 をつけ加えます。 つまり全体としては 「サッカー|ワールドカップ|1998」
という形になりました。 これで検索したようすを図3.14に示します。 今度は 232件まで減りました。 必要なら、 さらに検索条件を追加してページを絞り込むこともできます。
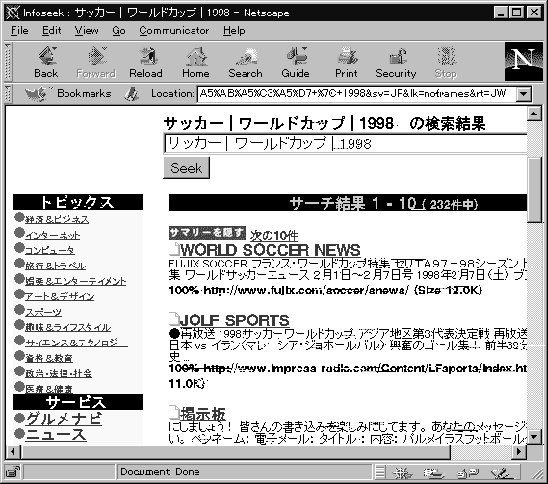
つまり、 ここで 「|」 を使ってキーワードをつなげているのは、 「単語Aを含むページ」「単語Bを含むページ」「単語Cを含むページ」 という集合を考えた場合、 それらの集合の積集合を求めているのだと考えることができます。
検索サービスではこのように、 単語さえ打ち込めば直接それに関係したページが探せ、 件数が多すぎればさらに絞り込むのも簡単にできるという利点があります。 また、 検索サービスでは世界中のWebページを探索ロボットと呼ばれるプログラムで自動的に調べて情報を収集するのが普通なので、 とくに登録を行なわなかったページでも調べられ、 その結果調べられるページの範囲がディレクトリサービスよりずっと多くなります。 その代わり、 あまりにも見つかったページが多すぎて本当に必要なものが埋もれてわからなかったり、 たまたま探した単語が含まれていたというだけで、 その内容とはほとんど関係ないページが検索されてしまう場合がある、 という弱点を持っています。
先の例では検索のための集合演算として、 積集合だけを使っていました。 しかし、 検索に際しては、 積集合以外にも和集合 (または)、 差集合 (~を除く) などの演算を使うこともできます。
たとえば、 ある場所で宿泊するのに 「民宿または旅館」 を探したければ、 「民宿」 と 「旅館」 の和集合を取ります。 また、 それら以外の何でもよいがホテルは好きではない、 という場合には 「宿泊施設」 から 「ホテル」 を除くという差集合を使います。
いずれの場合でも、 日本中どこでもいいわけではないでしょうから、 上で求めた集合と宿泊地を表す集合 (これも和、 差、 積などの集合演算によることができますね) との積集合を取ることになるでしょう。
ここまででWWWのさまざまな側面やさまざまな機能を見て来ました。 その一番の特徴は、 先にも述べたハイパーテキストの構造にあります。 ハイパーテキストの機能を活かすと、 次のような特徴が得られます。
ここまではハイパーテキストの特徴でしたが、 さらに、 WWWに固有な特徴としては、 次のことがあげられます。
一方で、 WWWは次のような弱点も持っています。
しかし全体としては、 WWWは 「誰でもがネットワークから有用な情報を取り出せる」 ようにした功労者であり、 インターネットブームのきっかけとなったのもうなずけるところです。